
本文截取了我和团队在国际化本地化测试的探索与实践的部分内容,重点介绍了Prism棱镜测试平台的建设和本地化数据测试的技术方案。
背景与挑战
在全球化的商业环境中,企业越来越重视产品的本地化适配,确保其产品满足不同地区用户的需求和使用习惯。产品的本地化不仅涉及语言和文化的多样性,还需考虑技术平台的兼容性、法律法规的合规性、用户的偏好习惯、时区、币种管理以及内容的频繁迭代变更等等。作为产品质量保障的测试工程师,如何通过层层的验证测试,给客户提供最卓越的用户体验,我们在执行本地化测试过程中面临着一系列的挑战:
- 资源限制:本地化测试通常需要专业的翻译人员和测试工程师。然而,许多企业在这方面的资源相对有限,导致测试的质量和效率难以得到保障。
- 场景繁杂:本地化测试涵盖多个方面,包括翻译、特殊字符处理、货币转换、时区调整、用户体验优化以及合规性测试。这些配置和切换常常耗时且复杂,容易导致遗漏,影响整体测试效果。
- 差异细微:不同地区的用户对产品的期望和使用习惯存在差异,确保同版本产品在不同市场功能的差异准确性是一项巨大挑战。
- 技术整合:目前市场上可直接用于本地化测试的工具比较少,且无法完全满足我们的需求,需要进行定制开发。
解决方案
如何减轻测试人员一遍遍的回归负担,提高测试效率变得愈发重要。除了常规的前后端功能自动化测试外,面对本地化测试的诸多痛点,让我们更加坚定了深入剖析并解决问题的决心。 综合考虑现有的测试技术框架和基础能力,我们搭建了Prism棱镜测试平台,该平台具备简洁、统一的前端操作页面,提供本地化数据测试、多市场推送测试和多语言翻译测试,以及进行中的多时区功能自动化验收,未来将致力于将其打造成为国际化综合的本地化测试平台。
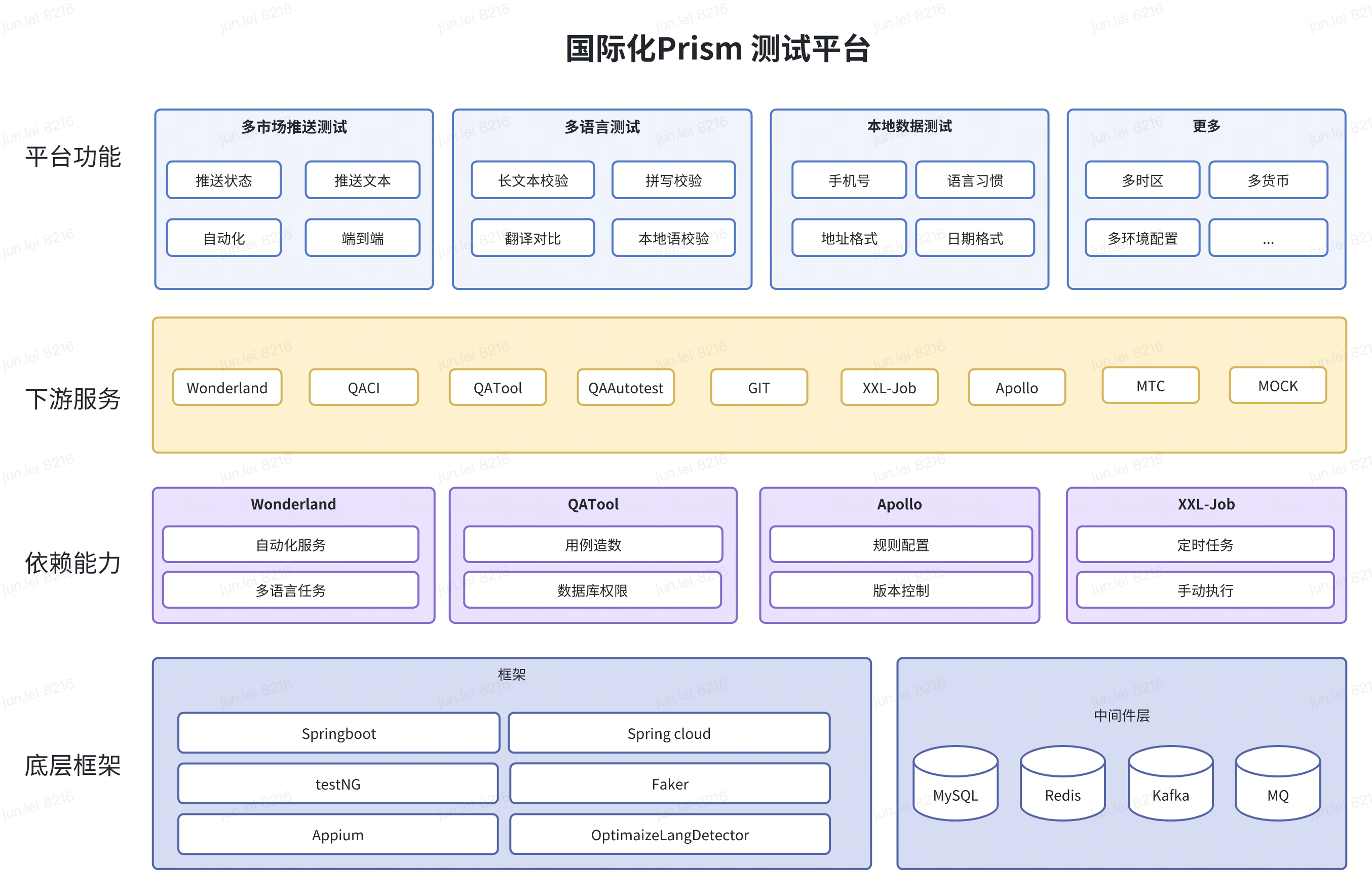
落地建设
接下来,我们将逐一介绍本地化测试探索过程中落地的几个工具。
本地化数据测试
随着我司全球化进程的加速,数据文本类的测试也变得越来越多样化,无论是传统的UI自动化还是接口自动化测试,在发现未知数据缺陷方面的成本都变得越来越高。如何高效、准确地验证多市场数据的兼容问题成为了一个亟待解决的难题。本节展开介绍一种落地的造数技术方案,借助公司MTC UI自动化和QACI接口自动化能力,自动检测潜在的多市场数据兼容性缺陷,为自动化测试注入新的活力。
数据原型收集
- 用户反馈:通过用户调研问卷、在线反馈系统、客户服务热线等渠道,收集了来自不同国家和地区的用户反馈,都是用户在实际使用过程中遇到的数据问题和建议,例如输入名称、地址、联系方式等。这些反馈往往直接反映了用户的真实需求和痛点。
- 市场调研:利用市场调研机构的数据报告和行业分析报告,了解市场趋势、竞争对手的数据处理方式和用户偏好。这有助于我们构建更加贴近市场需求的数据原型库。
- 已知缺陷:从历史测试记录中整理出常见的缺陷数据类型,如输入方式、格式错误、字符解析、语言不匹配等。这些缺陷类型可以作为构建数据原型库的重要参考。

需求分析
根据产品的功能模块和业务流程,来进一步确定我们需要测试的语言种类和文本类型。首先针对我们现有的海外市场,设计构造出不同语言的文本数据,如英语、繁体中文、泰文、越南文等。同时,我们还要考虑不同风格的文本表达,这些测试数据将用于验证APP在不同语言环境下的文本处理能力和用户体验,从而发现潜在的数据处理错误和边界条件问题。
工具选型
我们选用了目前市面上主流的多语言测试数据工具库Faker。近期,LOL英雄联盟著名中单选手Faker在S14全球总决赛再次带领SKT拿到队史第五座总冠军,堪称电竞界的传奇,而作为同名的Faker库在IT界也同样能力出众。这个工具库可以为我们提供丰富的语言资源和语法规则,帮助我们生成符合要求的测试数据。我们还发现Faker库支持全球大部分主流国家地区和语言,且有当地语言风格的字段设计,如街道名,邮编号码等。
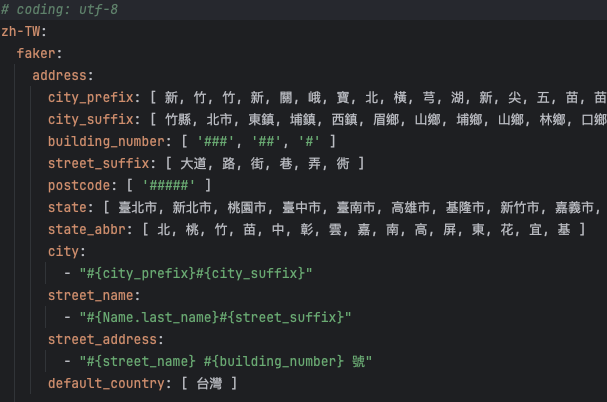
除了有丰富的语言资源外,Faker还有随机生成测试数据的能力,使得我们每次跑自动化流水线的时候,验证的数据场景都是不一样的,保证了测试的多样性,能探索更多潜在缺陷的可能。
数据构造
在二次开发设计和构造多语言测试数据的过程中,我们首先考虑到了Lalamove用户和司机端的基本核心文本输入类型,例如姓、名、全名组合、地址、电子邮箱、电话号码等等。
| |
其次,我们还考虑到了不同国家的身份证ID或护照ID的格式不尽相同,对此我们也做了定制化设计。Faker库对此类字母数字组合提供了三种有用的解决方法分别是 Letterify、Numberify 和 Bothify。首先Letterify 有助于生成随机的字母序列;而 Numerify 仅生成数字序列;最后,Bothify 是两者的组合,可以创建随机的字母数字序列,可用于模拟 ID 字符串等内容。
FakeValueService 需要有效的 Locale 以及 RandomService:
| |
在此代码片段中,我们创建一个新的 FakeValueService,其语言环境为 en-GB,并使用 bothify 方法生成唯一的虚假身份证ID。它的工作原理是将“?”替换为随机字母,将“#”替换为随机数字。
类似地,regexify 根据所选的正则表达式模式生成随机序列。在这个单元测试代码片段中,我们将使用 FakeValueService 创建一个遵循指定正则表达式的随机序列:
| |
我们的代码创建了一个长度为 10 的小写字母数字字符串,我们的模式根据正则表达式检查生成的字符串。
交互设计
- 传输效率:我们采用了高效的数据传输协议和压缩算法,同时还优化了数据传输的流程和网络环境,确保数据能够及时、准确地传输到目标平台。
- 传输安全:在进行UI自动化测试时,需要将测试数据从Prism平台传输到云测平台。为了确保数据传输的安全性和效率,我们采用了HTTPS协议进行加密传输,并设置了合理的传输间隔和重试机制。这样不仅可以保护数据的机密性,还可以确保数据能够及时到达目标平台,为测试过程提供坚实的数据支撑。
- 流程解析:
- Prism平台:为自动化平台提供了预设计的数据模板,同时为测试人员提供了友好的前端操作界面。当接收到数据构造请求后,Prism平台开始根据需求构造所需数据并生成,返回给自动化平台或测试人员使用。
- 自动化测试平台:包括移动端云测平台和接口自动化测试平台。首先根据Prism平台提供的数据模板预设好数据类型,并准备好所需的自动化场景脚本。接下来,不管是我们每天配置好的定时任务,还是手动触发的任务,只要命中了预设的多语言数据场景,就会自动向Prism平台发起接口请求。待接收到Prism生成的测试数据,则自动集成数据到我们的应用场景,并在测试报告中呈现结果。
- QA:同理,测试人员可以在业务测试过程中,使用Prism平台构造测试数据,并应用到自己的场景验证。
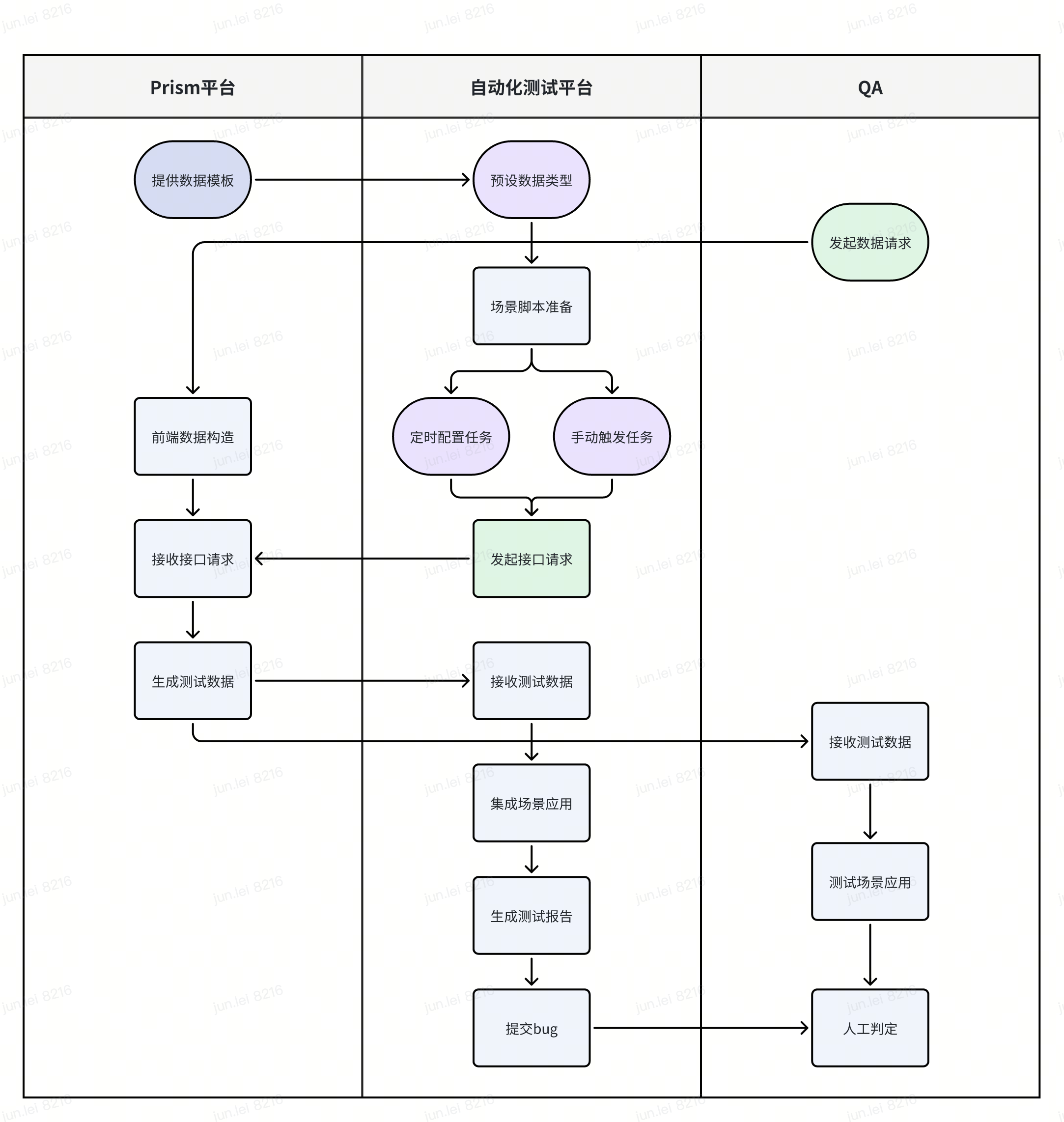
- 自动化集成
- 数据集成方案:对于UI自动化和接口自动化测试,我们设计了标准化的数据集成方案。利用已打通上下游服务壁垒的数据工厂工具将测试数据分别注入到UI界面中和接口端点,这个方案可以实现测试数据的无缝集成和自动化处理。
- 智能化:在数据集成过程中,我们也引入了智能化技术来优化数据处理流程。例如,利用机器学习算法对测试数据进行自动的分类和预测,以便更准确地识别和处理潜在的问题。

断言与结果展示
- 断言规则:根据多语言文本在端上和端到端接口的预期结果,我们设计了详细的断言规则。这些规则涵盖了文本内容、格式、特殊符号等多个方面,以确保测试结果的全面性和准确性。例如,对于文本内容,我们要求测试数据与预期结果完全一致;对于格式和特殊符号,我们要求测试数据符合特定的规范和标准。
- 案例:在日常的UI自动化流水线任务中,需要验证用户在和司机的聊天对话框中输入的文本数据是否能够正确显示在页面上。为了实现这一目的,我们设计了相应的断言规则来检查文本内容、格式和符号等方面的一致性。如果测试数据与预期结果不一致,我们将触发断言失败并生成相应的错误报告。
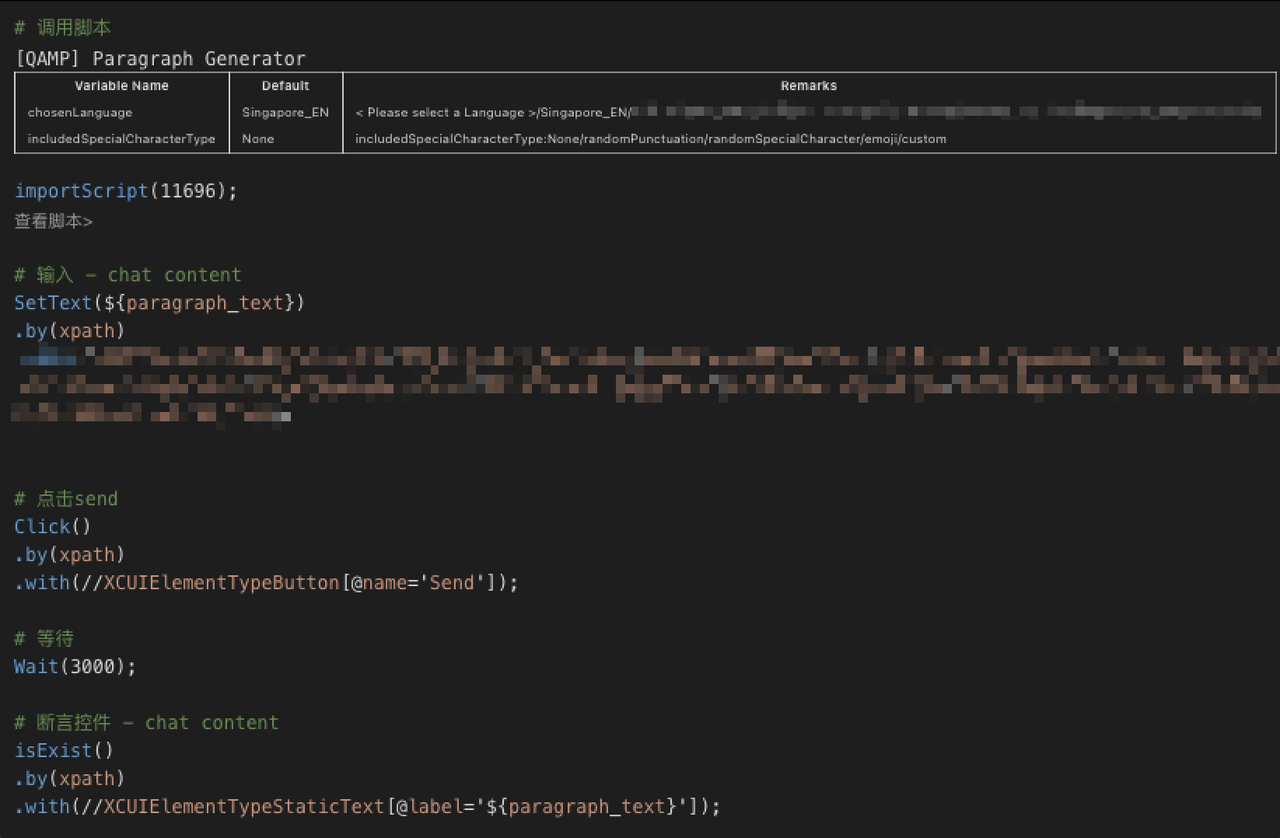
结果呈现
- 直观呈现:通过自动化平台的测试报告系统,我们将断言对比结果以直观、清晰的方式呈现出来。这些报告包括测试数据的详细信息、断言规则的描述、测试结果和错误信息等内容。用户可以根据报告中的信息快速定位潜在问题,为后续修复工作提供有力支持。
- 可视化分析:为了更直观地展示测试结果和趋势,我们还引入了可视化分析技术。利用图表和图形来展示测试数据的分布、缺陷类型和数量等信息,帮助用户更好地理解和分析测试结果。
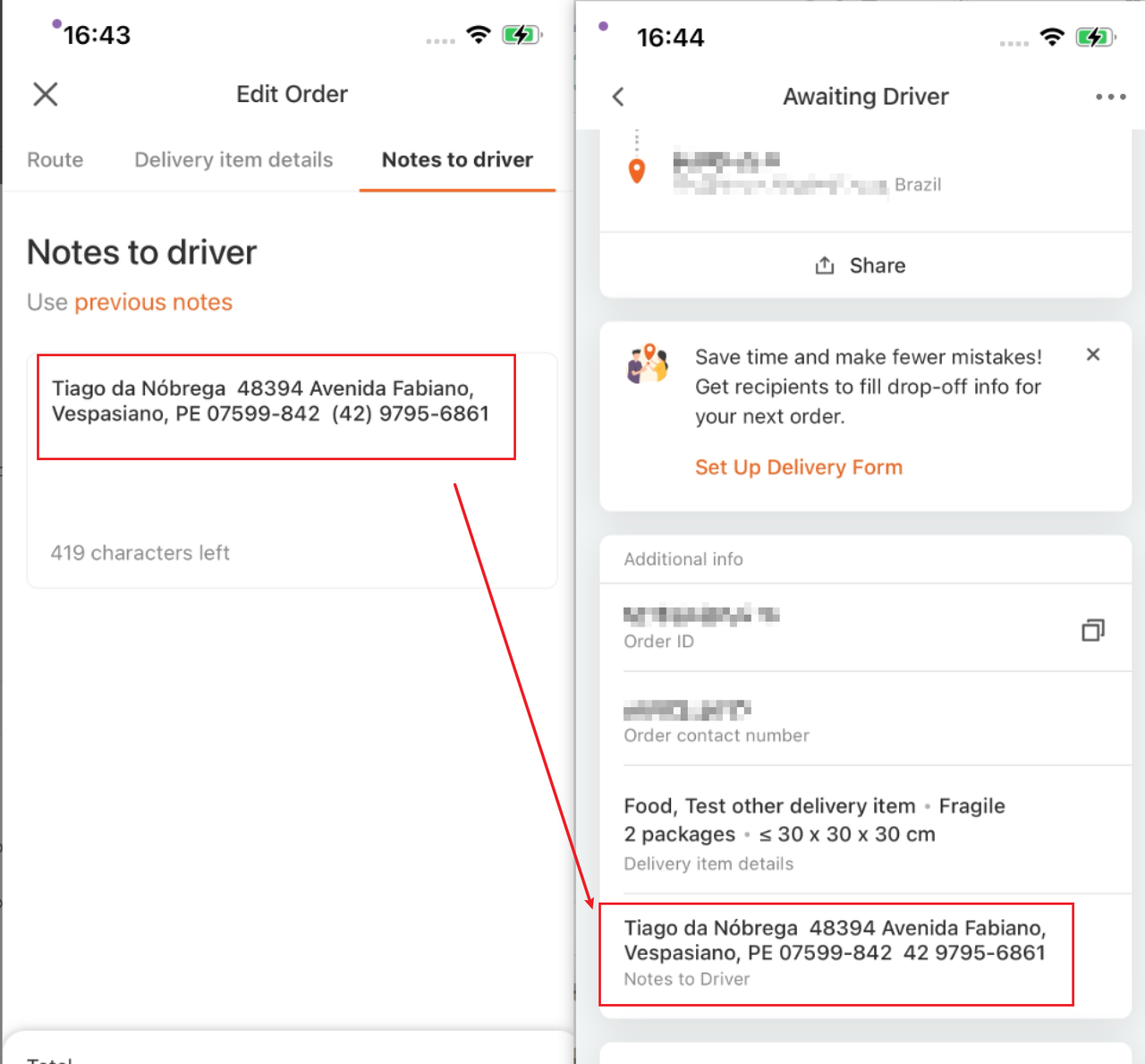
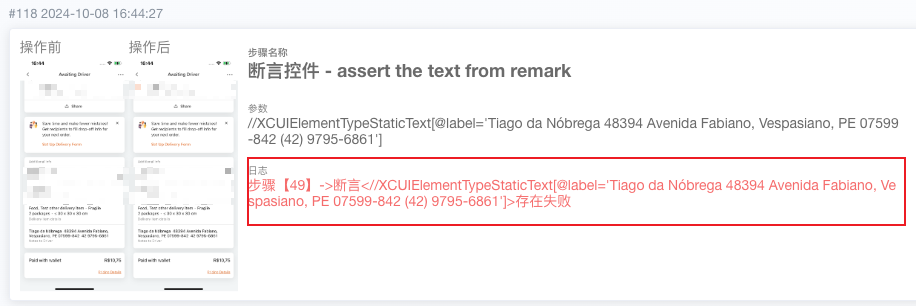
- 案例:在完成一轮对巴西市场回归验证的UI自动化测试后,云测平台自动生成了相应的测试报告,并提示有一处错误。报告直观呈现了测试数据、断言规则、测试结果和错误信息等内容。浏览报告可以快速定位到问题所在:模拟巴西用户给司机的留言文本场景中,发现等待司机页面电话号码的括号不见了。由此可见,接入本地化数据检测的自动化平台可以替代人工检测出更细节的文本使用缺陷。
参考文献
[1]: 稀土掘金 - 国际化本地化测试新探索
[3]: Faker 官方文档
[4]: Faker 使用教程
[5]: Java Faker GitHub 仓库